Summary of the quantities and sources of visual elements:
Recent advances in text-to-vision generation excel in visual fidelity but struggle with compositional generalization and semantic alignment. Existing datasets are noisy and weakly compositional, limiting models' understanding of complex scenes, while scalable solutions for dense, high-quality annotations remain a challenge.
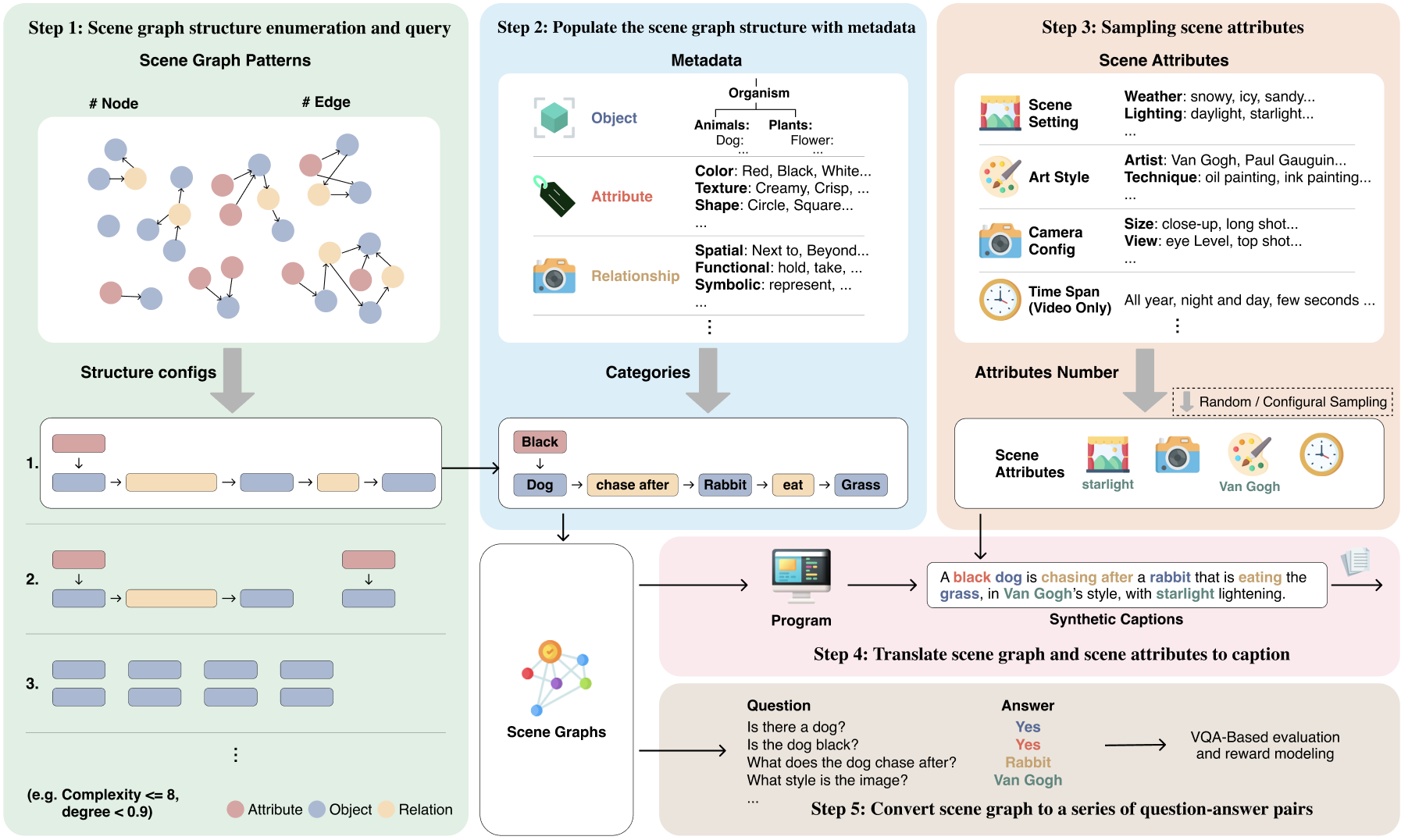
We introduce Generate Any Scene (GAS), a data engine that systematically enumerates scene graphs representing the combinatorial array of possible visual scenes. GAS dynamically constructs scene graphs of varying complexity from a structured taxonomy of objects, attributes, and relations. Given a sampled scene graph, GAS translates it into a caption for text-to-image or text-to-video generation; it also translates it into a set of visual question answers that allow automatic evaluation and reward modeling of semantic alignment.
Using GAS, we first design a self-improving framework where models iteratively enhance their performance using generated data. SD v1.5 achieves an average 4% improvement over baselines and surpasses fine-tuning on CC3M. Second, we also design a distillation algorithm to transfer specific strengths from proprietary models to their open-source counterparts. Using fewer than 800 synthetic captions, we fine-tune SD v1.5 and achieve a 10% increase in TIFA score for compositional and hard-concept generation. Third, we create a reward model to align model generation with semantic accuracy at a low cost. Using GRPO algorithm, we fine-tune SimpleAR-0.5B-SFT and surpass CLIP-based methods on DPG-Bench. Finally, we apply these ideas to the downstream task of content moderation where we train models to identify challenging cases by learning from synthetic data.
Modern text-to-vision models produce high-fidelity visuals but struggle with compositional generalization and semantic alignment. Existing real-world datasets (like CC3M) are noisy, weakly compositional, and lack dense, high-quality annotations. Constructing a compositional dataset requires that we first define the space of the visual content. Scene graphs are one such representation of the visual space, grounded in cognitive science. A scene graph represents objects in a scene as individual nodes in a graph. Each object is modified by attributes, which describe its properties. Relationships are edges that connect the nodes. Scene graphs provide explicit compositional structure.
We introduce Generate Any Scene (GAS), a controllable scene-graph-driven data engine that produces synthetic captions and QA for training, evaluation, reward modeling, and robustness improvement in text-to-vision systems. GAS systematically enumerates scene graphs representing the combinatorial array of possible visual scenes.
To construct a scene graph, we use three main metadata types: objects, attributes, and relations. We further introduce scene attributes that capture global visual contexts, such as art style, to facilitate comprehensive caption synthesis. We build a hierarchical taxonomy that categorizes metadata into distinct levels and types, enabling fine-grained analysis.
Summary of the quantities and sources of visual elements:
| Metadata Type | Count | Source |
|---|---|---|
| Objects | 28,787 | WordNet |
| Attributes | 1,494 | Wikipedia, curated lists |
| Relations | 10,492 | Synthetic Visual Genome |
| Scene Attributes | 2,193 | Places365, curated lists |
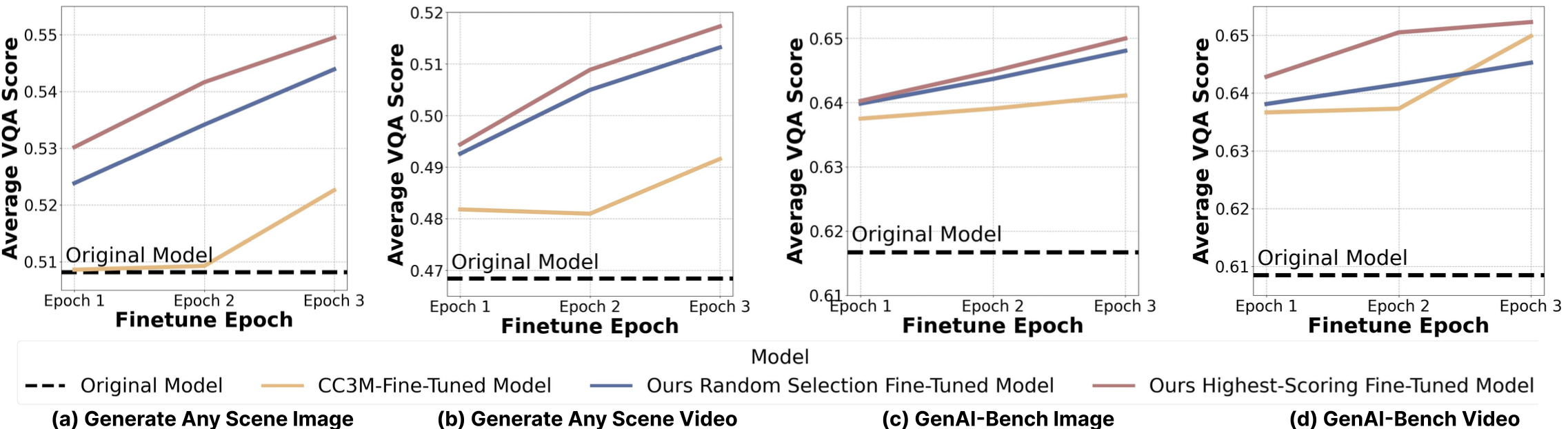
GAS-generated captions can be used to iteratively fine-tune a model on its own synthetic distribution. Applying this loop to Stable Diffusion v1.5 yields approximately 4% improvement in compositional quality over the pre-trained baseline, and surpasses fine-tuning on the real-image CC3M dataset — without any human-annotated data.

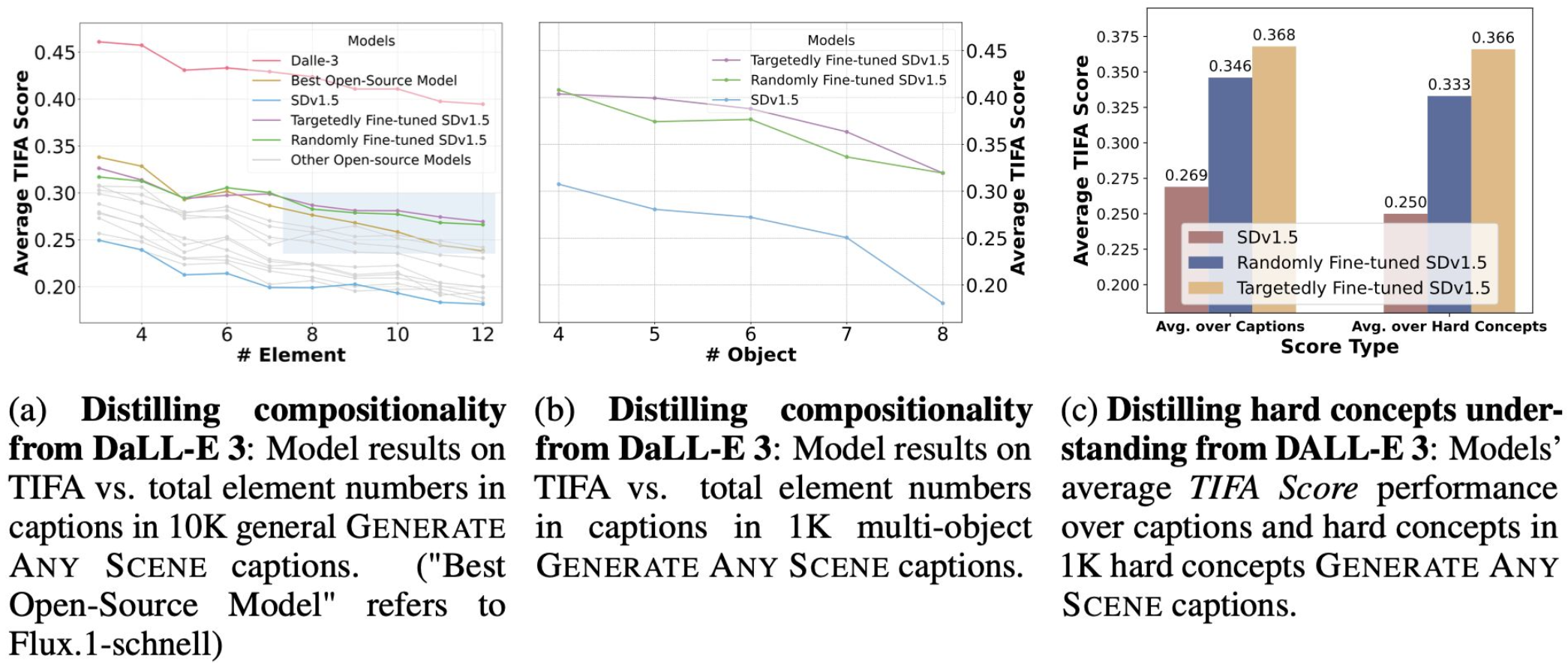
GAS enables targeted capability transfer from strong models to weaker ones. Using GAS-structured prompts, we generate fewer than 800 synthetic image-caption pairs from DALL-E 3 and fine-tune SD v1.5 on them. This compact distillation achieves a ~10% improvement in TIFA score on compositional generation tasks — demonstrating that structured synthetic data is highly efficient for closing compositional gaps.


Scene-graph QA pairs from GAS serve as verifiable reward signals for reinforcement learning with GRPO. Applied to SimpleAR-0.5B-SFT, this approach achieves a improvement on DPG-Bench compared to CLIP-based reward methods — highlighting that structured, interpretable rewards derived from scene graphs are more effective than perceptual similarity metrics alone.
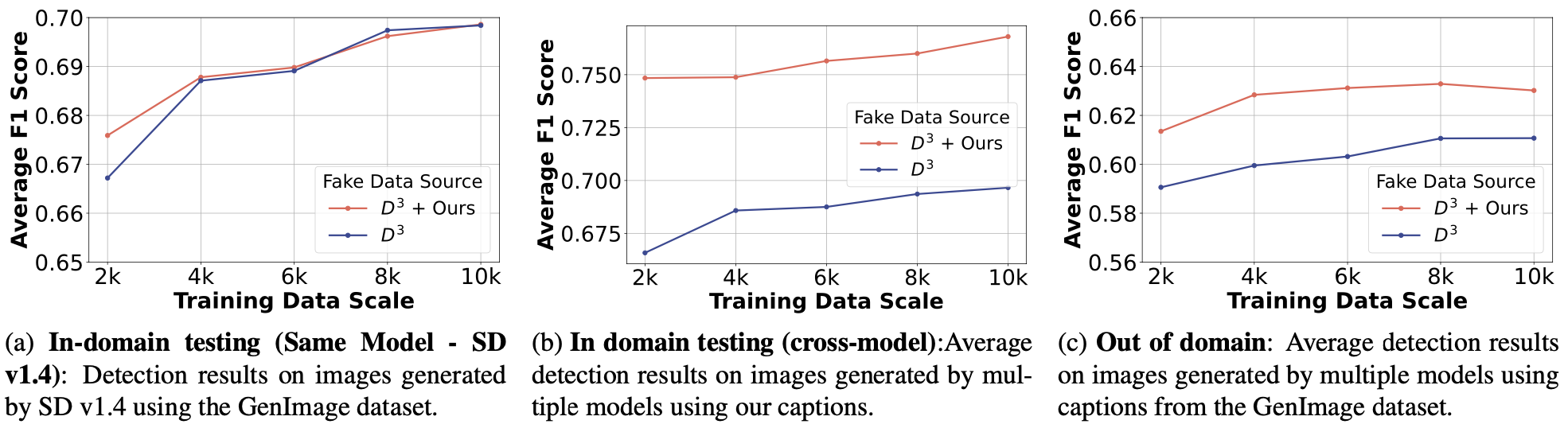
GAS synthetic data can train detectors that distinguish AI-generated images from real ones. A lightweight ViT-T detector trained on GAS-generated images improves F1 scores across both cross-model and cross-dataset evaluation scenarios, demonstrating that controlled, diverse synthetic data is a reliable resource for content provenance and moderation tasks.
@inproceedings{gao2026generate,
title={Generate Any Scene: Scene Graph Driven Data Synthesis for Visual Generation Training},
author={Ziqi Gao and Weikai Huang and Jieyu Zhang and Aniruddha Kembhavi and Ranjay Krishna},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026}
}